
by Joanne Yu & Roman Egger
Full paper published by: Roman Egger and Joanne Yu, Frontiers in Sociology, https://doi.org/10.3389/fsoc.2022.886498
Have you been wondering what would be the best way to analyse short, text-heavy, and unstructured content from social media? Certainly, social media has opened an entirely new path for social science research, especially when it comes to the overlap between human relations and technology. In the 21st century, data-driven approaches provide brand-new perspectives on interpreting a phenomenon. Yet, methodological challenges emerge in both the data collection and analysis process. To shed light on the efficacy of different algorithms, his article takes tweets with #covidtravel as well as the combination of #covid and #travel as the reference points and evaluates the performance of four topic modeling; namely latent Dirichlet allocation (LDA), non-negative matrix factorization (NMF), Top2Vec, and BERTopic.
Introduction to the four models
LDA is a generative probabilistic model for discrete datasets. It is a three-level hierarchical Bayesian model, where each collection item is represented as a finite mixture over an underlying set of topics, and each topic is represented as an infinite mixture over a collection of topic probabilities. Since the number of topics need not be predefined, LDA provides researchers with an efficient resource to obtain an explicit representation of a document.
In contrast to LDA, NMF is a decompositional, non-probabilistic algorithm using matrix factorization and belongs to the group of linear-algebraic algorithms. NMF works on TF-IDF-transformed data by breaking down a matrix into two lower-ranking matrices. Specifically, NMF decomposes its input, which is a term-document matrix (A), into a product of a terms-topics matrix (W) and a topics-documents matrix (H). W contains the basis vectors, and H contains the corresponding weights.
Top2Vec is a comparatively new algorithm that uses word embeddings. That is, the vectorization of text data makes it possible to locate semantically similar words, sentences, or documents within spatial proximity. For example, words like “mom” and “dad” should be closer than words like “mom” and “apple.” Since word vectors that emerge closest to the document vectors seem to best describe the topic of the document, the number of documents that can be grouped together represents the number of topics.
BERTopic builds upon the mechanisms of Top2Vec and provides document embedding extraction with a sentence-transformers model for more than 50 languages. BERTopic also supports UMAP for dimension reduction and HDBSCAN for document clustering. The main difference between Top2Vec is the application of a class-based c-TF-IDF algorithm, which compares the importance of terms within a cluster and creates term representation.
Results explanation of LDA and NMF
Starting from LDA, three hyperparameters are required. A grid search was performed for the number of topics (K) as well as for beta and alpha. The search for an optimal number of topics in our study started with a range from two to 15, with a step of one. During the process, only one hyperparameter varied, and the other remained unchanged until reaching the highest coherence score. To facilitate a clear interpretation of the extracted information from a fitted LDA topic model, pyLDAvis was used to generate an intertropical distance map.
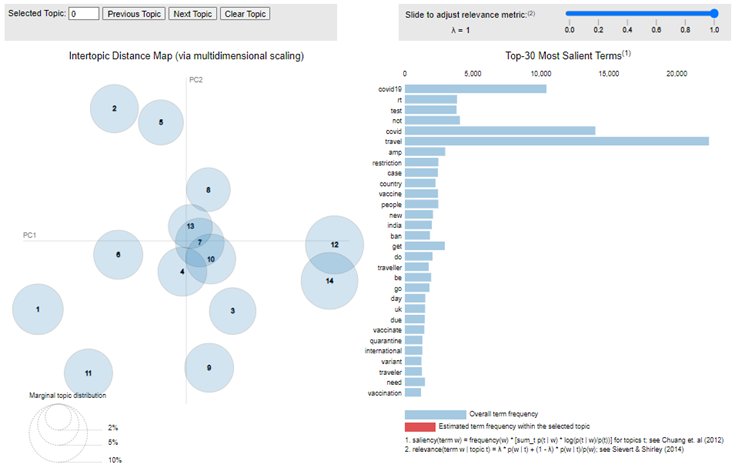
As for NMF, an open-source Python library, Gensim, was used to estimate the optimal number of topics. By computing the highest coherence score, 10 topics could be identified in our research. Due to a clear distinction between all the identified topics in the NMF model (see detailed results in our paper), we conclude that the results obtained from NMF are more in line with human judgment, thereby outperforming LDA in general. Yet, as both models do not allow for an in-depth understanding of the phenomenon, the next section focuses on the topic models that use embedding representations.
Results explanation of BERTopic and Top2Vec
By relying on an embedding model, BERTopic and Top2Vec require an interactive process for topic inspection. Both algorithms allow researchers to discover highly relevant topics revolving around a specific term for a more in-depth understanding. Using Top2Vec for demonstration purposes, presuming that we are interested in the term “cancel” during COVID-19, the Top2Vec produces relevant topics based on the order of their cosine similarity, ranging from 0 to 1. Thereafter, the most important keywords for a particular topic can be retrieved. But, ultimately, an inspection of individual tweets is also highly recommended. For example, the keywords for the topic “cancel” include the following:
[“refund,” “booked,” “ticket,” “cancelled,” “tickets,” “booking,” “cancel,” “flight,” “my,” “hi,” “trip,” “phone,” “email,” “myself,” “hello,” “couldn,” “pls,” “having,” “guys,” “am,” “sir,” “supposed,” “hopefully,” “me,” “excited,” “postpone,” “so,” “days,” “dad,” “paid,” “option,” “customers,” “request,” “bihar,” “thanks,” “amount,” “due,” “waiting,” “to,” “got,” “back,” “impossible,” “service,” “hours,” “complete,” “before,” “wait,” “nice,” “valid,” “book”].
Turning to BERTopic, since some of the topics are close in proximity, visualization and topic reduction would provide a better understanding of how the topics truly relate to each other. To reduce the number of topics, hierarchical clustering can be performed based on the cosine distance matrix between topic embeddings. Our study took 100 topics as an example to provide an overview of how and to which extent topics can be reduced.

Conclusion
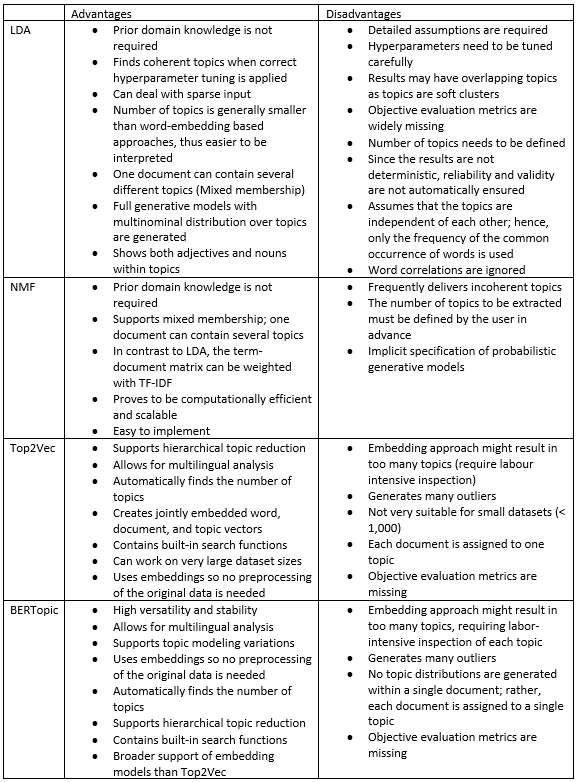
For an overall evaluation based on human interpretation, this study supports the potency of BERTopic and NMF, followed by Top2Vec and LDA, in analyzing Twitter data. While, in general, both BERTopic and NMF provide a clear cut between any identified topics, the results obtained from NMF can still be considered relatively “standard.” The table below summarizes the pros and cons of applying LDA, NMF, BERTopic, and Top2Vec in order to help facilitate social scientists in the necessary preprocessing steps, proper hyperparameter tuning, and comprehensible evaluation of their results. Please refer to our study for a complete step-by-step guide and detailed results.
How to cite: Egger, R., & Yu, J. (2022). A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts. Frontiers in Sociology, 7.