
by Joanne Yu & Roman Egger
Full paper published by: Roman Egger and Joanne Yu, Tourism Review,
https://doi.org/10.1108/TR-05-2021-0244 
Have you ever wondered how to analyse caption text on Instagram? Texts shared on Instagram are typically more complex. Compared to blogs, newsletters, or online comments, the textual content of Instagram posts mainly consist of very short texts and is unstructured by nature.
From a marketing viewpoint, although we are all aware of the potential in generating insights from Instagram in order to better understand consumer experiences, the complexity of texts often is the biggest hurdle for marketers to analyse Instagram content. In our study, we present three topic modelling approaches in analysing Instagram textual data. We evaluate latent Dirichlet allocation (LDA), correlation explanation (CorEx), and non-negative matrix factorization (NMF) to support the decision-making when selecting appropriate techniques.
To provide an overview of the three topic modelling techniques, our study applies dark tourism experiences as the study context based on narratives shared on Instagram. A total of 26,581 public posts tagged with #darktourism were crawled. After data cleaning, we analysed 12,835 posts published by 4,711 personal accounts. Data were then pre-processed and transformed into vectors.
Introduction to LDA, CorEx, and NMF
Among several types of topic models, LDA is agreed as the most popular algorithm. Its core strength is that the algorithm can infer the latent topic structure where no predefined classes are required. Through an iterative process, words are re-assigned to a topic until convergence. However, one major flaw lies in its high dependence on words and their frequency in a corpus, which may result in overlapping clusters.
In addition to LDA, CorEx is a newly semi-supervised approach used in recent social media research. CorEx is based on an information-theoretic framework, suggesting a process of gaining information when the outcome is unknown before the analysis. Thus, it searches for informative representations that can best explain certain phenomena. Another strength is that CorEx provides the model with anchor words. This flexibility allows researchers to develop creative strategies and enforces topic separability.
Finally, we introduce NMF in the study. NMF is a linear-algebraic model capable of improving topic coherence. One advantage of NMF is that it can transform sparse data into a dense matrix without losing latent information. That is, when learning in noisy domains (e.g., social media), NMF can detect meaningful topics without prior knowledge of the original data.
Process and evaluation of LDA
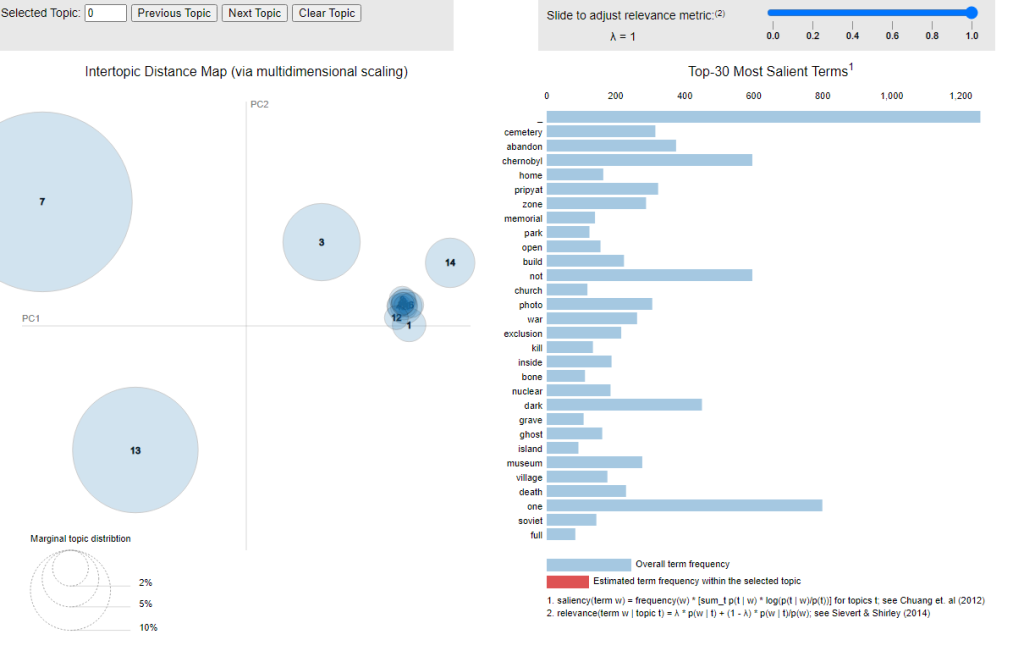
First, a grid search on three essential hyperparameters (number of topics (K), alpha, beta) was performed. To identify the optimal hyperparameters, one always varies and the other hyperparameters remain constant. After running several experiments, the best coherence score with 15 topics, was reached. Next, the grid search yielded a symmetric alpha value and a beta value of 0.91. However, through a visual inspection using an intertropical distance map with pyLDAvis, several overlapping topics were identified. An example can be seen from the figure below. For readers who are interested, an interactive visualisation of the overlapping topics can be seen at https://tinyurl.com/darkt-LDA. Thus, we conclude that LDA cannot determine a suitable topic solution.
Process and evaluation of NMF
In NMF, the two factors – W and H – are always nonnegative, minimising the risk of interpreting topics with negative entries for certain words. Typically, researchers approximate the factors, although there is no guarantee whether the input matrix can be recovered. That is, the number of subjects needs to be determined in advance. In our study, Gensim was used to estimate the optimal number of topics.
Although seven topics (without overlapping) could be identified, human judgment concluded that the topics were not specific enough for meaningful implications. After all, while NMF appears to perform better than LDA, NMF model only contains a small number of topics. Because NMF relies on the Frobenius norm, word weights are not probability distributed. In this case, the findings suffer from a poor-quality model where multiple topics are merged into one.
Process and evaluation of CorEx
The number of topics for CorEx depends on the distribution of total correlation. After comparing different numbers of extracted topics, the inspection in our study returned a 17- topic solution with the highest correlation. To effectively extract latent factors, incorporating domain knowledge through anchor words could be used. Assessing the strength of anchor words facilitates researchers to decide to what extent the words are related to a topic. Because the evaluation of anchor words corresponds to a more advanced theory- or domain-knowledge-driven approach (which is not present in LDA and NMF), this step was not proceeded in the research.
Which one works the best?
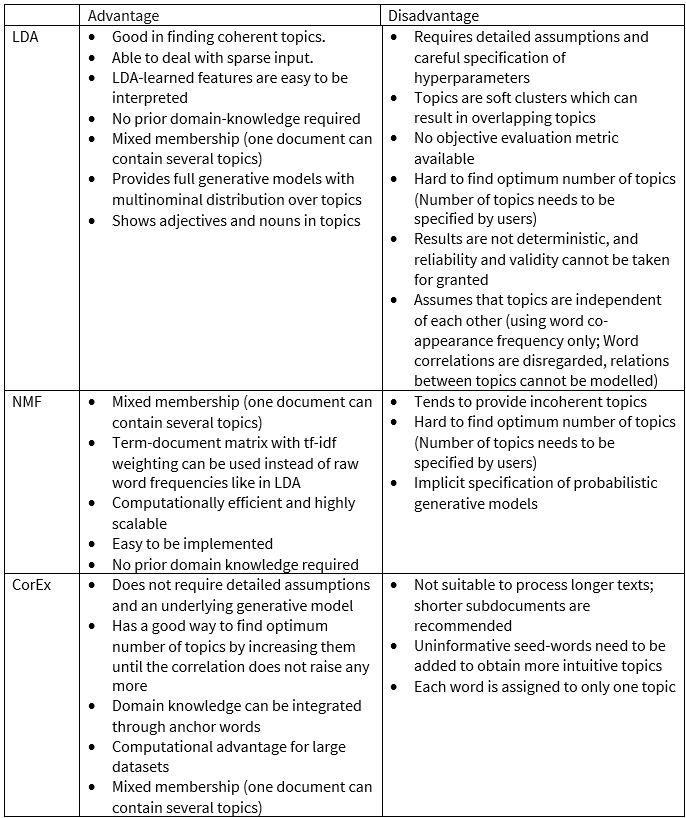
In a nutshell, we support the effectiveness of CorEx in uncovering hidden insights when processing Instagram data. However, it is important to keep in mind that there is no “best” topic modelling technique because the performance may vary, depending on the nature of the data sets. Meanwhile, because topic modelling still serves as a means for qualitative research, human judgement and interpretation are of high relevance. Below we summarise the advantages and disadvantages of the individual approach.
How to cite: Egger, R., & Yu, J. (2021). Identifying hidden semantic structures in Instagram data: a topic modelling comparison. Tourism Review, ahead-of-print.