by Roman Egger
As described in detail in chapter 10 (Classification), for a classification task you need labeled data as training data. Let’s assume we have three different classes “hotel”, “tourist” and “travel agency”. This data can be text data or images, for example. But what if the learner finds among the test data examples of classes that were not present during the training. We humans are usually very good at recognizing things and classifying them correctly, even if we have never seen them before. In zero shot learning (ZSL), observed and unobserved classes are related by auxiliary information and difference features are identified. For images, a description about the appearance of objects can help distinguish one class from another, even if no examples of the unknown class were present in the training data. An example often used for explanation is that between horses and zebras. A human would be able to distinguish a zebra from a horse even if he had never seen a zebra, provided the auxiliary information that zebras are black and white striped was known. Auxiliary information can be, for example, attibutes and metadata, text descriptions, or vectors of word category labels.
ZSL occurs in two steps: First, knowledge about attributes is acquired during training. Then, in the second step of inference, the knowledge is used to partition instances into new categories. Natural Language Inference (NLI) examines whether a hypothesis for a given premise is true (consequent), false (contradictory), or indeterminate (neutral).
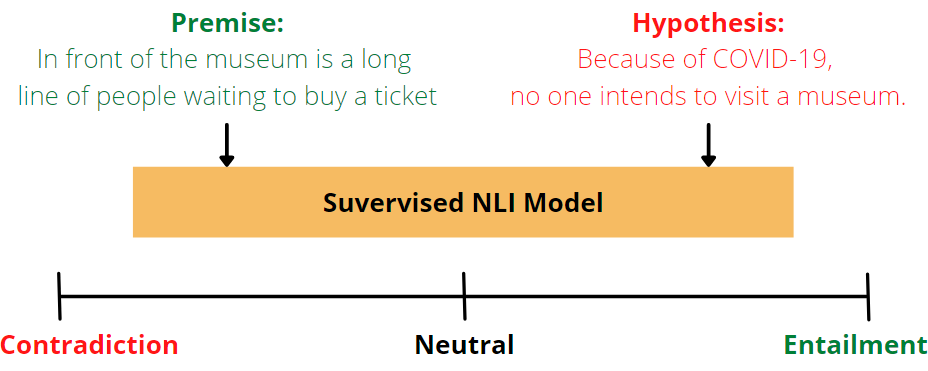
Another example would be, if we want to predict the sentiment between the positive and negative groups for the example sentence “I love the city of Salzburg”, this can be tested as follows:
Premise: I love the city of Salzburg
Hypothesis 1: This example is positive.
Premise: I love the city of Salzburg
Hypothesis-2: This example is negative.
Now, for each class, a hypothesis template such as “This example is….” is created to predict the correct class for the premise. If the inference is a consequence, the premise belongs to that class. In this case positive.
Now let´s have a look how we can easily implement Zeros Shot Classification for Texts using Huggingface in just two lines of code.
classifier = pipeline("zero-shot-classification")
classifier("Data Science is altering the tourism industry", candidate_labels=["Business",'Politics', 'Technology'])
We use the “zero-shot-classification” pipeline from Huggingface, define a text and provide candidate labels. For this task, the NLI-based zero-shot classification pipeline was trained using a ModelForSequenceClassification. Numerous available models can be used to fine-tune the NLI task. In this case, the sentence “Data Science is altering the tourism industry” should be correctly classified in one of the following classes “Business”, “Politics”, or “Technology”. The output shows us the probability scores for each category.
{'sequence': 'Data Science is altering the tourism industry',
'labels': ['Technology', 'Business', 'Politics'],
'scores': [0.6754791140556335, 0.2831524610519409, 0.04136836156249046]}
I can also recommend CLIP from Openai, a neural network that learns visual concepts from natural language supervision. CLIP can be used for any visual classification benchmark by simply providing the names of the visual categories to be recognized.