
by Leyla Atabay & Beykan Çizel
Journal of Tourism and Services, Vol. 11 No. 21 (2020)
Link to Paper:
https://jots.cz/index.php/JoTS/article/view/163
With this paper, we aimed to obtain meaningful themes and emotions from traveler reviews of hotels in three mass tourism destinations (Antalya, Majorca, Sharm El Sheikh). For that, we asked three main questions.
1) What are the features of the service components of the mass tourism destination hotels?
2) What are the emotions that arise from the analysis of hotel reviews according to mass tourism destinations?
3) What are the similarities and differences between the tourists’ emotions about the service components of hotels operating with the same concept in different mass tourism destinations?
Figure 1: Hotel Selection – Source: own processing
In order to answer these questions and scale the data, we determined the most liked 9 hotels (3 in each) in 3 destinations with similar characteristics and collected a total of 3588 reviews. At this point, we preferred the “rvest” package (rvest.tidyverse.org) in the leading R program in data mining applications and coded a script data from a hotel review website. We also used dplyr, tidytext, readxl, tm, syuzhet, wordcloud, lubridate, ggplot2, reshape2, rlang, and purrr packages for the other analyzes process.
After collecting the data, we moved on to the “pre” data cleaning process. First, we fixed or deleted the corrupted characters in the corpus data. Then we combined the words that would be synonymous with each other and the plural forms of the words. Thus, we created a file ready for cleaning in the R program.
In the data cleaning process, R offers some auxiliary functions. We would like to present some examples of these below.
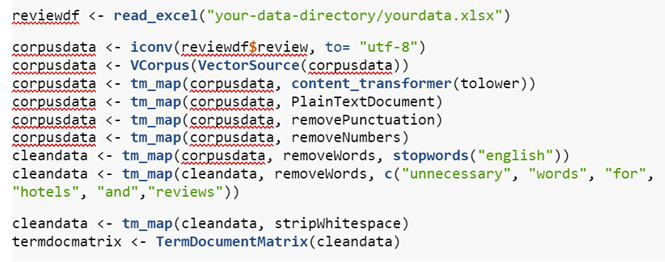
As can be observed in the codes, we first defined an excel file, namely “reviewdf”. Then we specified which column to read and moved on to the steps of cleaning the corpus data. First, we converted all letters to lowercase. In the second step, we defined it as plaintext. In the third, fourth, and fifth steps, respectively, we removed punctuation, numbers, stopwords. In step six, we deleted any other words we believed were unnecessary for this data. Thus, we also had to clean up the “whitespace” created in the previous steps.
Immediately after cleaning, we defined a term-document matrix in the clean dataset and created wordclouds to understand the main themes of reviews.

Figure 2: Wordclouds – Source: own processing
However, wordclouds were not enough to understand the importance of themes and which service components they are related to. For this reason, we thought it would be more informative to create a network analysis from the data and calculate the link strengths between nodes (namely words in reviews). So we created word networks for three destinations.
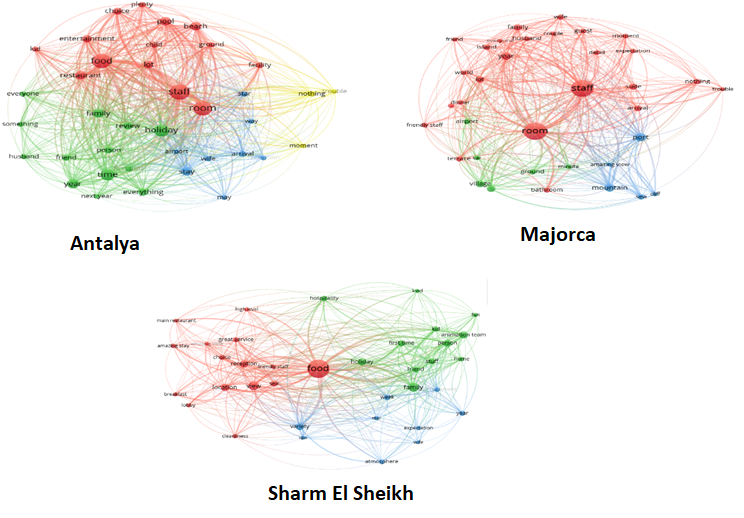
Figure 3. Review Networks – Source: own processing
To answer the second research question, we used syuzhet package in R (cran.r-project.org/web/packages/syuzhet/vignettes/syuzhet-vignette.html). This package is lexicon-based, and it allowed us to discover 8 basic emotions of Plutchik (1980) in the most risk-free way.
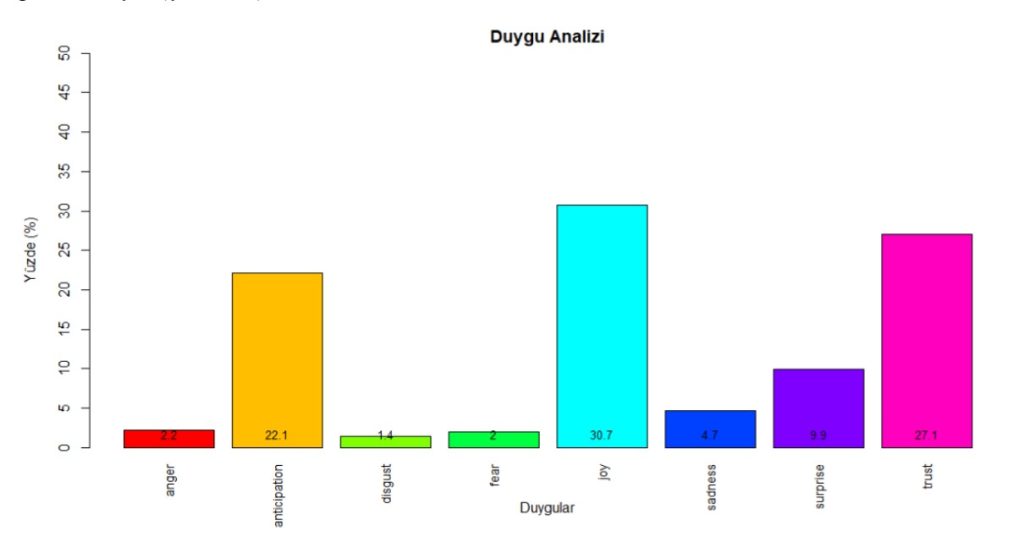
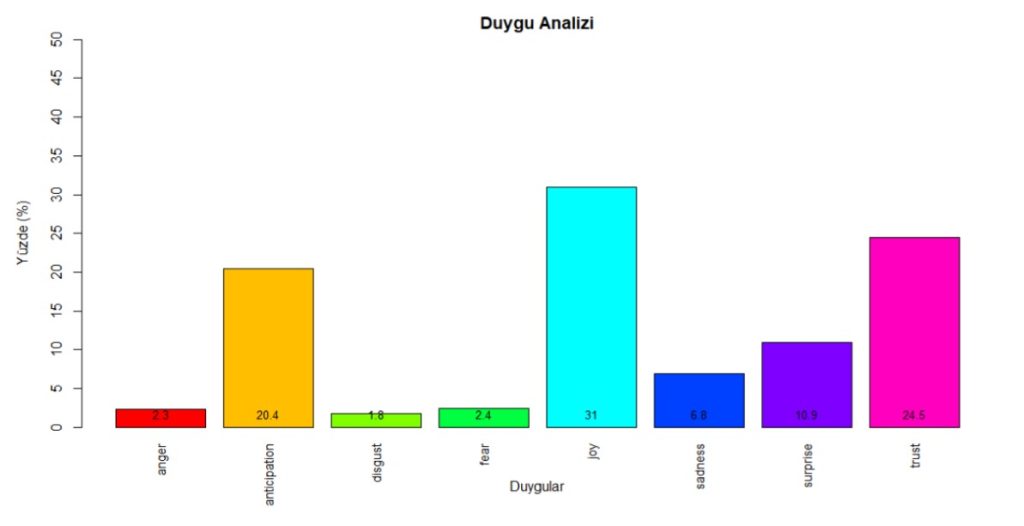
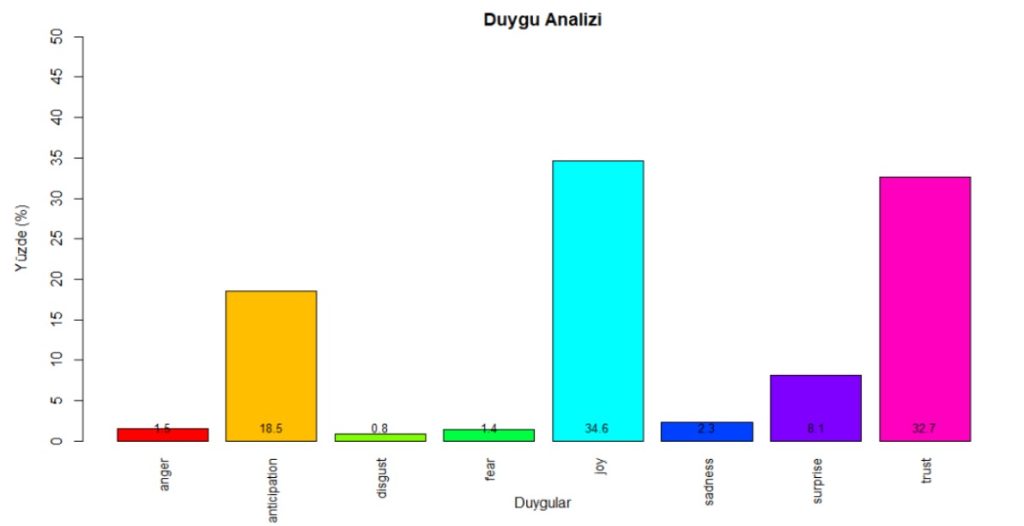
Figure 4: Sentiments – Source: own processing
Comparison of reviews with the help of previous analyzes was hardly possible. More precisely, it was clear that the comparison was based on the visual reading capability of the reader. To overcome this problem and answer the third research question, we applied “Correspondence Analysis”.
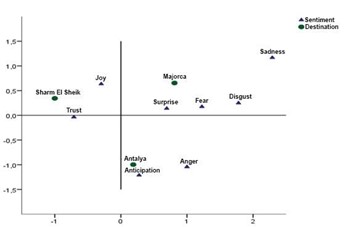
Figure 5: Correspondence Analysis
Our findings highlighted the most important service features and prevailing emotions for hotels in Mediterranean destinations. Furthermore, the results of the multiple correspondence analysis revealed how emotions towards hotel services differ in three different destinations.
References
Atabay, L., & Çizel, B. (2020). Comparative Content Analysis of Hotel Reviews by Mass Tourism Destinations, Journal of Tourism and Services, 21(11), 147-166. doi:10.29036/jots.v11i21.163 
Plutchik, R., (1980). Emotion: A Psychoevolutionary Synthesis, New York: Harper & Row.
https://cran.r-project.org/web/packages/syuzhet/vignettes/syuzhet-vignette.html