
by Roman Egger
The development of machine learning algorithms is making great strides and especially in the field of natural language processing (NLP) and image processing, groundbreaking developments can be observed from one year to the next.
Deep learning approaches, in particular, have led to revolutionary developments, however, the fact that the preparation of vision datasets is very labor- and cost-intensive remains a serious problem. Classical computer vision algorithms recognize patterns of the pixels of an image (these are the features) by analyzing shapes, distances between shapes, colors, contrast ratios, and much more. Millions of images must therefore be laboriously labeled. A photo with a beach and a palm tree needs to be labeled as such to be used as data input.
At the beginning of 2021, Open.ai presented a groundbreaking development with CLIP (Constrative Language – Image Pre-training). CLIP is a neural network trained on 400 million image-text pairs from the Internet. The images used have been trained using natural language supervision, giving CLIP “zero-shot” capabilities like GPT2 or GPT3. This multi-modality training CLIPs performance can be compared with ResNet-50 on ImageNet without the need for 1.28 million labeled data, making CLIP a game-changer for visual classification tasks. In short, CLIP pre-trains an image encoder and a text encoder, resulting in images and texts being represented in the same vector space. The evaluation of CLIP took place as a zero-shot image classifier, but there are numerous other applications of CLIP.
To try out the features and benefits of CLIP, I considered the following scenario in a tourism context. Visual communication is becoming increasingly important in tourism marketing. Instagram and Co have given classic destination marketing a hard time because the relevance of user-generated content is beyond doubt. UGC and the messages of destination management organizations (DMOs) are fighting for attention. In this respect, the analysis of UGC is becoming increasingly important for destinations. On the one hand, to get a feel for the perceived image of tourists and to shape the development of offers accordingly (read our paper about clustering destination image using ML), on the other hand, to post tailored information via social media channels that bring high engagement.
Study & Method
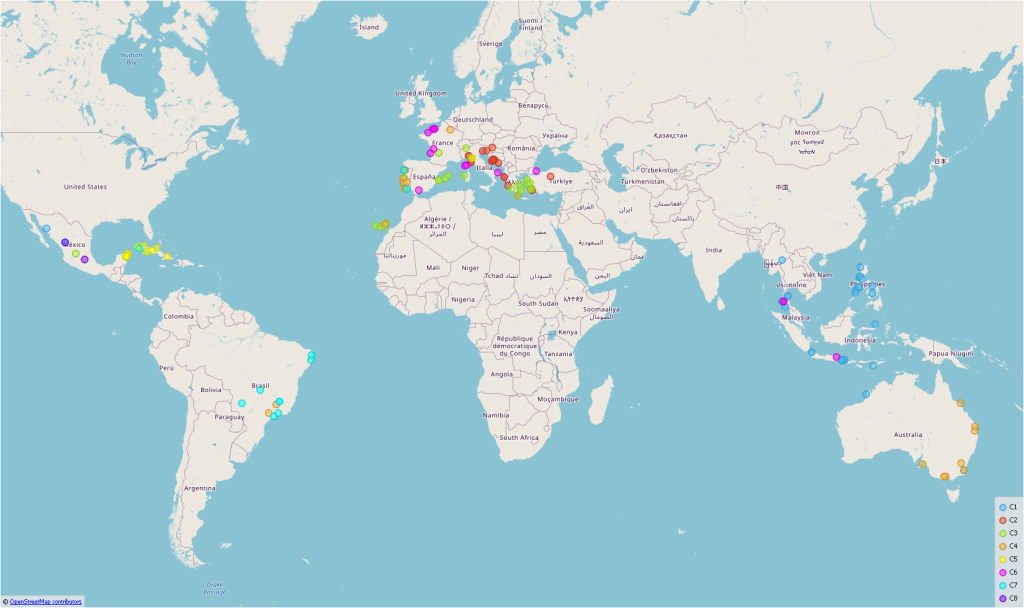
Pictures are worth a thousand words, but without context, they can become interchangeable. For my example, I chose images of beaches. To do this, I crawled 600 Instagram posts with the hashtag #wonderfulbeaches. Geoapify was used to extract the geo-location (lat/long) from the location descriptions of the posts. Then I selected 10 photos of beaches (only landscape without people or buildings) for the countries (Australia, Brazil, Croatia, Cuba, France, Greece, Indonesia, Italy, Mexico, Philippines, Portugal, Spain, Thailand, and Turkey). These 140 pictures were downloaded and saved together with texts. For each image, there were three textual descriptions. “This is a beach in [country]. So for example -” This is a beach in Greece” the two other sentences contained also a positive and negative sentiment. “This is a wonderful beach in Greece”, “This is a terrible beach in Greece”. This was done to see the textual impact of country names in the embedding of the images as well as the sentiment impact. Since CLIP uses the same vector space (512 dimensions) for both images and texts, vectors were created for the images alone, for the texts alone, and once the vector sum for image and text. The idea was to extend the image vector by the textual “context vector”.
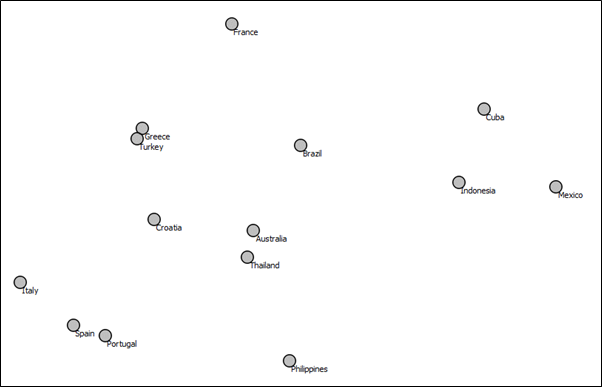
The vectors were then reduced with t-SNE. Figure 1 shows the two-dimensional text-vector space for the countries used. It is interesting to see how the semantic proximity of two terms partly reflects the geographical proximity. Something like Turkey and Greece or Spain and Portugal. (If you are not aware of embeddings, read here)
Also, the image embeddings of CLIP already provided interesting insights. Using Louvain clustering (a community detection method, I normalized the data, used 20 PCA components in pre-processing and 15 k-neighbors) similar types of beaches are already grouped together. Figure 2 shows that the clustering of the beaches already corresponds to the geographic spaces. For example, beaches in the Philippines and Thailand (purple on the top) have the same characteristics as beaches in Croatia (light blues on the right) (Figure 3).
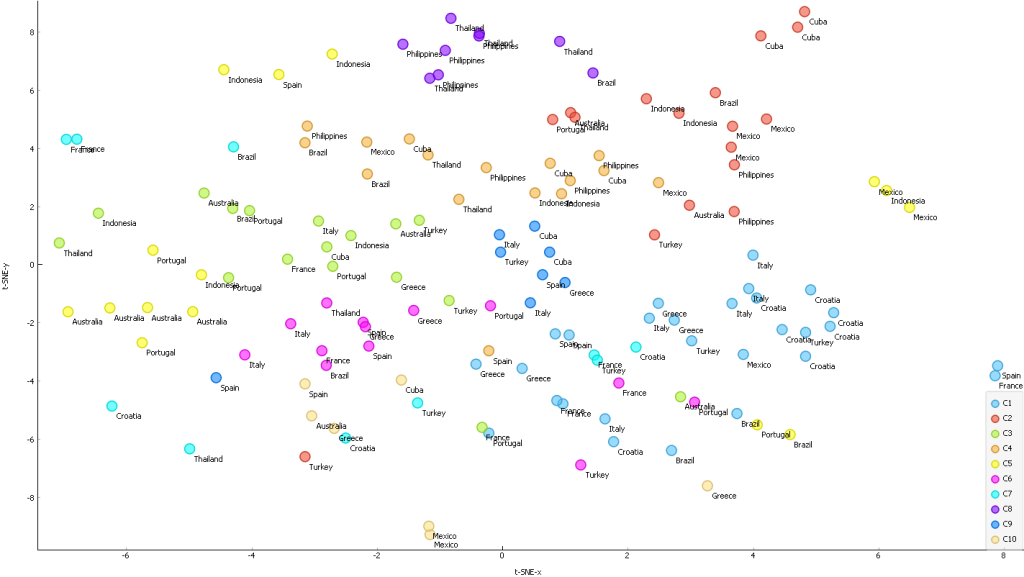

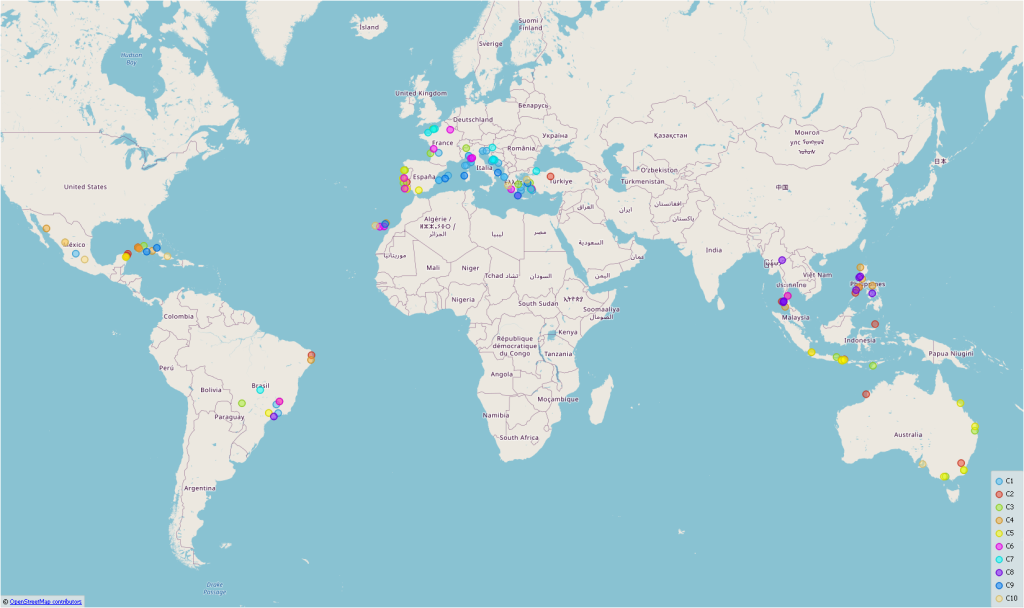
However, it became really interesting when I looked at the combined image-text vectors. Figure 4 shows the geographical clustering of the images, Figure 5 the clustering of the image-text vectors on a map. It is clearly visible that the individual beaches can be assigned much better to the actual countries. Of course, the clusters are not that perfect if the regions are very close together (eg. Italy, Croatia)
Now I tried to evaluate the results with a classification task. Three models were developed for this purpose. Once a Neural Network, once SVM, and a Random Forest. The model parameters are shown in Table 1.
| Model parameters | ||
| Neural Network | SVM | Random Forest |
| Hidden layers: 20 Activation: ReLu Solver: Adam Alpha: 0.0003 Max iterations: 200 Replicable training: True | SVM type: ν-SVM, ν=0.25, C=1.0 Numerical tolerance: RBF, exp(-auto|x-y|²) Numerical tolerance: 0.001 Iteration limt: 100 | Number of trees: 200 Maximal number of considered features: unlimited Replicable training: No Maximal tree depth: unlimited Stop splitting nodes with maximum instances: 5 |
In the following, I tried to classify the images and the images with text information, using the country as a target variable. As expected, the results based purely on the images are relatively poor. The best results are obtained with the Random Forest model.
| Model | AUC | CA | F1 | Precision | Recall |
| SVM | 0.6847802197802196 | 0.2714285714285714 | 0.2766353591198311 | 0.29982041767756057 | 0.2714285714285714 |
| Random Forest | 0.773186813186813 | 0.30714285714285716 | 0.30856541493235523 | 0.32583289726146863 | 0.30714285714285716 |
| Neural Network | 0.6831868131868132 | 0.18571428571428572 | 0.19110876806863095 | 0.20733353947639663 | 0.18571428571428572 |
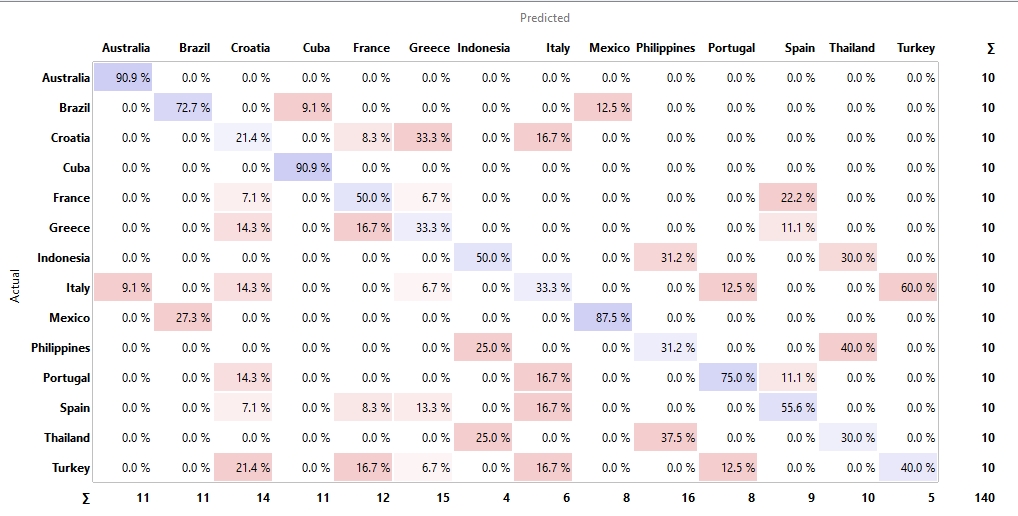
In order not to integrate the vector for a country too unambiguously in the combination of image and text, an alternative combination was generated by CLIP in the next step. For this purpose, not the country but the continent in which the country is located was embedded as text information. For a beach in Spain, Portugal, or Italy “Europe” was vectorized as text, for countries like Thailand or Indonesia “Asia”. It turns out that the Random Forest model again performs best, followed by the SVM. I must say, however, that I did not try to tune the models extensively.
| Model | AUC | CA | F1 | Precision | Recall |
| SVM | 0.8264835164835165 | 0.4357142857142857 | 0.4443248535805696 | 0.46818161996733415 | 0.4357142857142857 |
| Random Forest | 0.911923076923077 | 0.5285714285714286 | 0.522848413073977 | 0.5442473201401773 | 0.5285714285714286 |
| Neural Network | 0.7914285714285715 | 0.2571428571428571 | 0.2552245140480435 | 0.27814762268543786 | 0.2571428571428571 |
Also from the Confusion Matrix, it can be seen that the correct assignment to the according countries was now already quite ok in some cases.
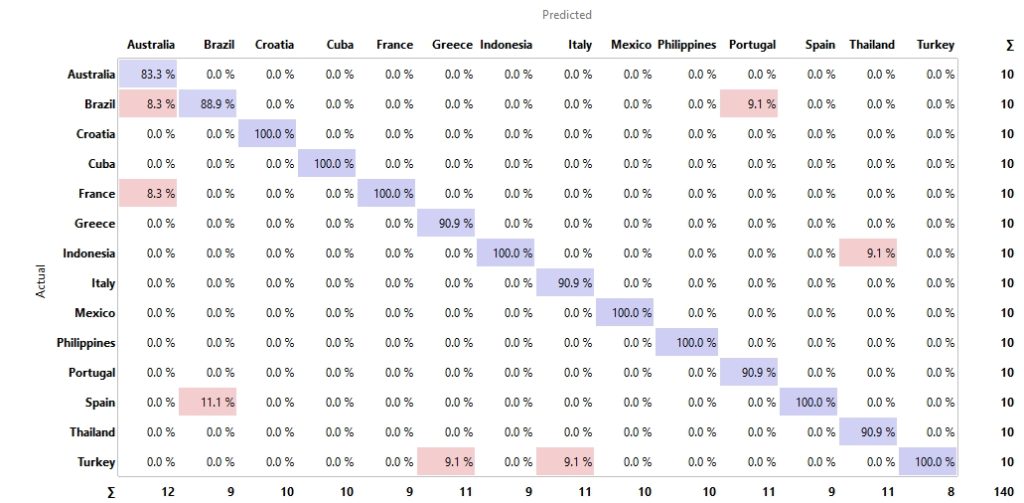
Finally, the image-country vectors were classified and it shows that here almost all images of beaches could be assigned to the correct countries.
| Model | AUC | CA | F1 | Precision | Recall |
| SVM | 0.9565934065934066 | 0.8071428571428572 | 0.8061427389761813 | 0.8162004662004663 | 0.8071428571428572 |
| Random Forest | 0.9908791208791207 | 0.95 | 0.9494081524156712 | 0.9541847041847044 | 0.95 |
| Neural Network | 0.8942307692307692 | 0.5214285714285715 | 0.5222826109155263 | 0.5519886859172574 | 0.5214285714285715 |
It was also interesting to see how the positions in the vector space shifted when a positive or negative connotation was included in the sentence (wonderful vs. terrible). The shift is noticeable but not so strong as to displace the dominance of the country’s information. This study thus shows that it is possible to extend image embeddings with text embeddings using CLIP and thus make them more precise. In the future, for example, the images of Instagram posts could be enriched with text information, or photos on review platforms could be combined with text descriptions. Projects like “Concept” from Maarten Grootendorst use CLIP to develop a kind of topic modeling for images. In the future, the combination of images and text could provide a much better insight than classical topic modeling attempts with LDA, NMF, etc. can do today.