
by Joanne Yu & Roman Egger
Full paper published by: Barbara Neuhofer, Roman Egger, Joanne Yu, and Krzysztof Celuch, Annals of Tourism Research, https://doi.org/10.1016/j.annals.2021.103310
How can tourism be reborn? How can we reach states of awe? How can events become experiences that change people? Transformation is no longer a buzzword. In fact, we can use experience design principles to intentionally design transformative experiences – from opening glimpses and triggers towards long-term integration. In this research project, we look into attendees’ experiences of Burning Man shared on Instagram. By adopting a data analytics approach, we identify the socio-physical factors of human transformative experiences within and beyond the festival environment.
A three-phase methodological procedure
Phase 1 Data collection: To determine Instagram posts related to Burning Man, the hashtag #burningman2019 was used. In 2019, the 29th edition of Burning Man took place from August 25th through September 2nd. Based on this timeframe, we extracted posts published six months before the event, during, and six months after, resulting in a total of 53,326 posts. The extracted data, including captions (i.e., texts, hashtags, emojis), posts’ dates, posts’ URLs, and types of user account (i.e., business/personal).
Phase 2 Data pre-processing: First, language identification was applied in Python using Spacy to eliminate non-English posts. Next, business accounts and their corresponding posts, duplicates, and posts without a description were removed. This resulted in 35,802 usable posts: 8953 thereof published before the event, 2840 published during the event, and 24,009 published after the event. Thereafter, a list of stopwords was prepared, and irrelevant signs and unknown characters, numbers, and references to usernames with @ were removed. Slang words were reformed and hashtags, as well as emojis, were extracted.
Phase 3 Deep topological data analysis: A deep topological data analysis approach is a combination of topological data analysis and deep generative models. Concerning the former, the topic list is used as an embedding space for dimension reduction and further clustering. With the latter, the purpose is to learn the true data distribution of the training set to generate new data points with some variation. Depending on the data type, common approaches thereof include variational autoencoders and generative adversarial networks. The Vietoris-Rips algorithm was used to connect nearby data points to build topological structures, and nested complexes were used to identify persistent elements of the data structure using Morse Theory. Finally, the manifolds of the original dimensions were simplified and visualized.
An overview of the results
The software DataRefiner was used to build thematic clusters and to visualize the topological structure of the data. The text was tokenized, and text parameters were identified by weighing the tokens. These parameters are the key terms that represent the different clusters and can be expressed via a correlation value between −1 and 1. By means of an iterative process, the number of clusters was adjusted until the number of noise points reached a suitable minimum, ultimately reaching 30 unique clusters.
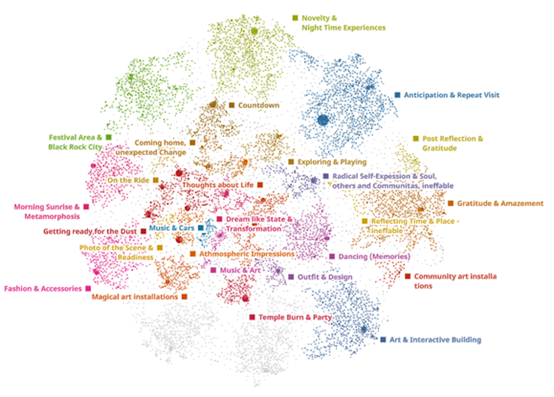
From an epistemological viewpoint, the selection of the number of clusters and the interpretation thereof requires deep knowledge of a topic domain from a researcher. The naming of each cluster was based on extracted keywords, found parameters, and text summaries, following crosschecks and consensus among the research team. Finally, the graphical representation of the cluster map was visualized, presenting the topographic structure with similar clusters located close to each other. Clusters that are spatially opposite from each other show that their relevant parameters are fundamentally different, and the correlation of the parameters is close to −1. The detailed results can be found in our paper.
Our research outperforms prior studies that may suffer from the intrinsic drawbacks of traditional techniques. For instance, although LDA has been widely used in tourism research, it relies primarily on word co-appearance frequency. Relations between topics thus remain unknown. By showcasing the potential and usefulness of deep topological analysis in tourism research, in cases where the goal is to explore implicit messages based on short-text and unstructured Instagram data, our study supplies a robust and transparent compass to navigate through the epistemological and methodological questions and decision-making process – from theory-led research design and data collection to data analysis and theory generation.
How to cite: Neuhofer, B., Egger, R., Yu, J., & Celuch, K. (2021). Designing experiences in the age of human transformation: An analysis of Burning Man. Annals of Tourism Research, 91, 103310.