by Xingbo Wang
Multimodal sentiment analysis aims to recognize people’s attitudes from multiple communication channels such as verbal content (i.e., text), voice, and facial expressions. It has become a vibrant and important research topic in natural language processing, which also benefits various applications, such as social robots, customer analysis, healthcare, and tourism applications.
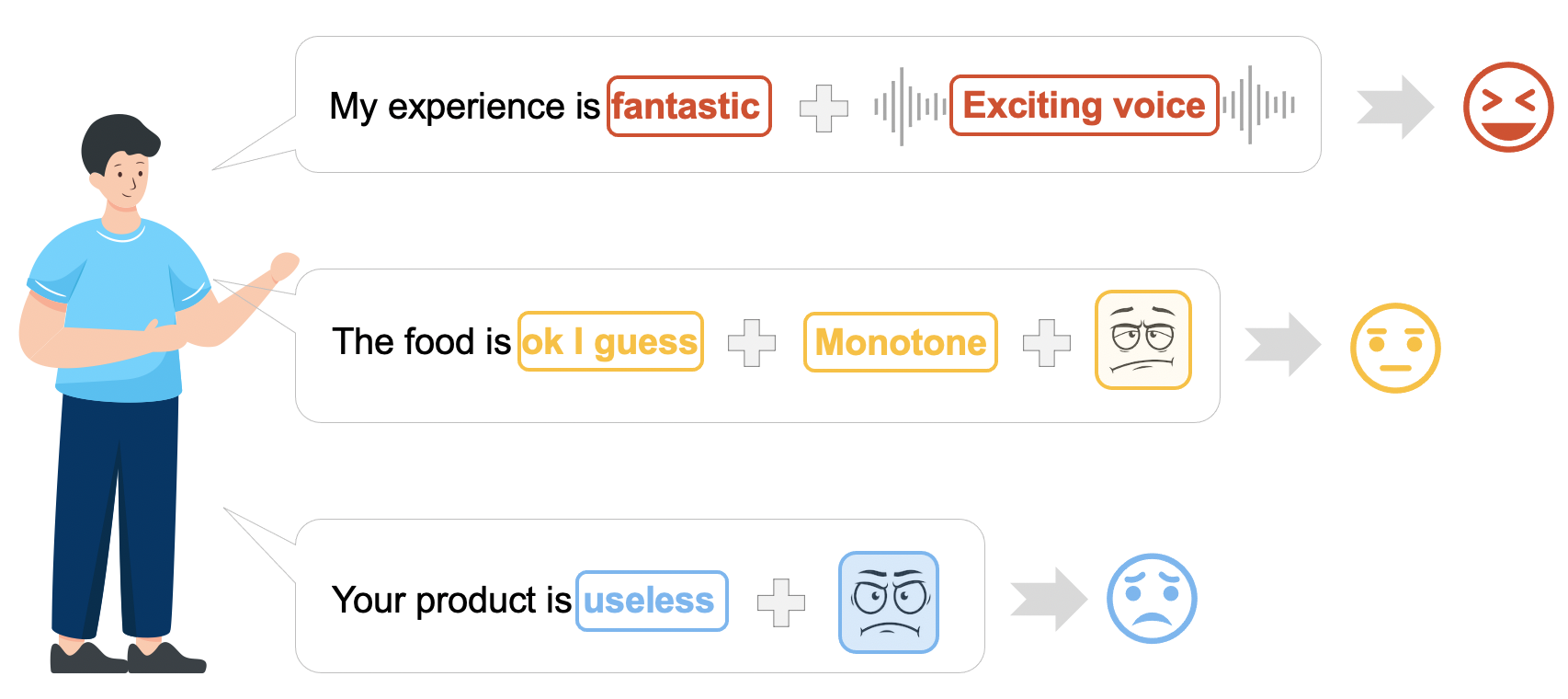
What is M2Lens?
Currently, deep-learning-based models achieve superior performance over the traditional methods in multimodal sentiment analysis. Representative examples include transformers, CNNs, and RNNs. However, these models often work like black-boxes, hindering users from understanding the underlying model mechanism and fully trusting them in decision-makings.
Post-hoc explainability techniques, such as LIME, SHAP, and IG, help identify important features (e.g., words or image patches) that influence model predictions. However, these methods often target providing local explanations on instances (e.g., sentences) in unimodal scenarios. They do not scale well to produce global explanations on how intra- and inter-modal in- teractions influence the model decisions, for example, how the models will behave when positive words and sad voices are presented.
We present M2Lens, a novel explanatory visual analytics tool to help both developers and users of multimodal machine learning models better understand and diagnose Multimodal Models for sentiment analysis.
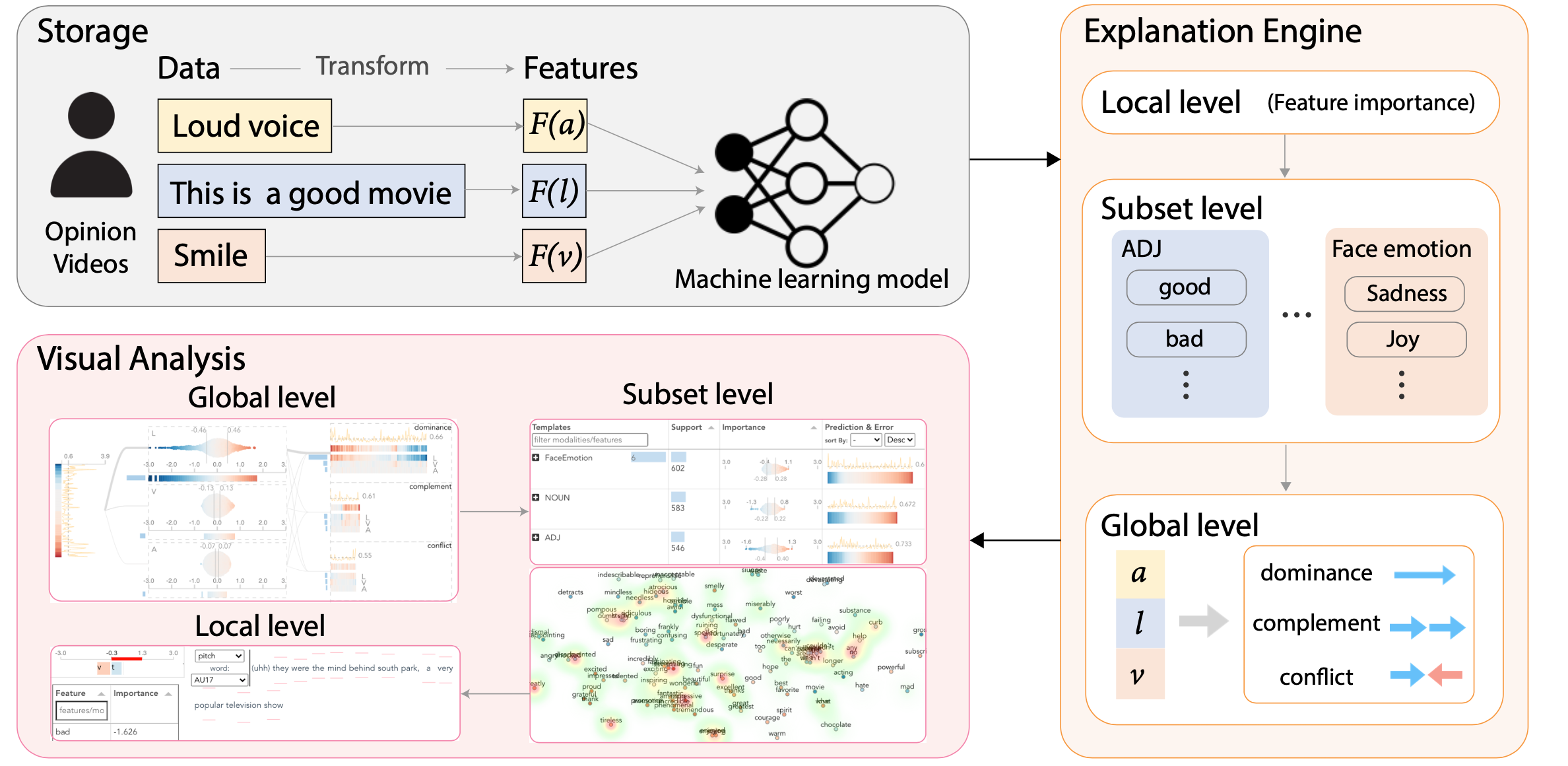
How does it work?
Multi-modal sentiment analysis combines the heterogeneous data and captures two primary forms of interactions in different modalities:
Intra-modal interactions refer to the dynamics of one modality.
Inter-modal interactions consider the correspondence between different modalities across time.
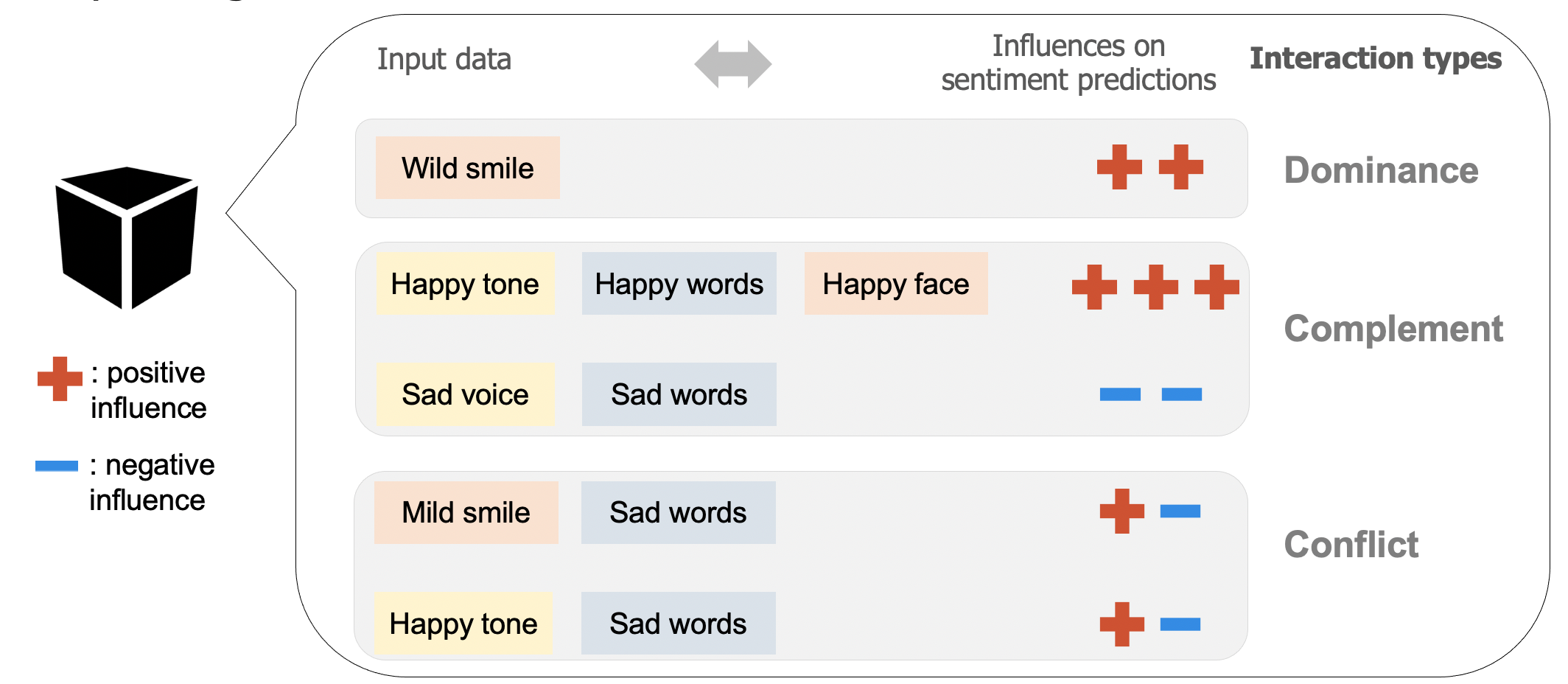
We formulate a set of rules to characterize three typical types of interactions among modalities, including dominance, complement, and conflict.
The dominance suggests that the influence of one modality dominates the polarity (i.e., positive sentiment or negative sentiment) of a prediction.
The complement indicates that two or all three modalities affect a model prediction in the same direction.
The conflict reveals that the influences of modalities differ from each other.
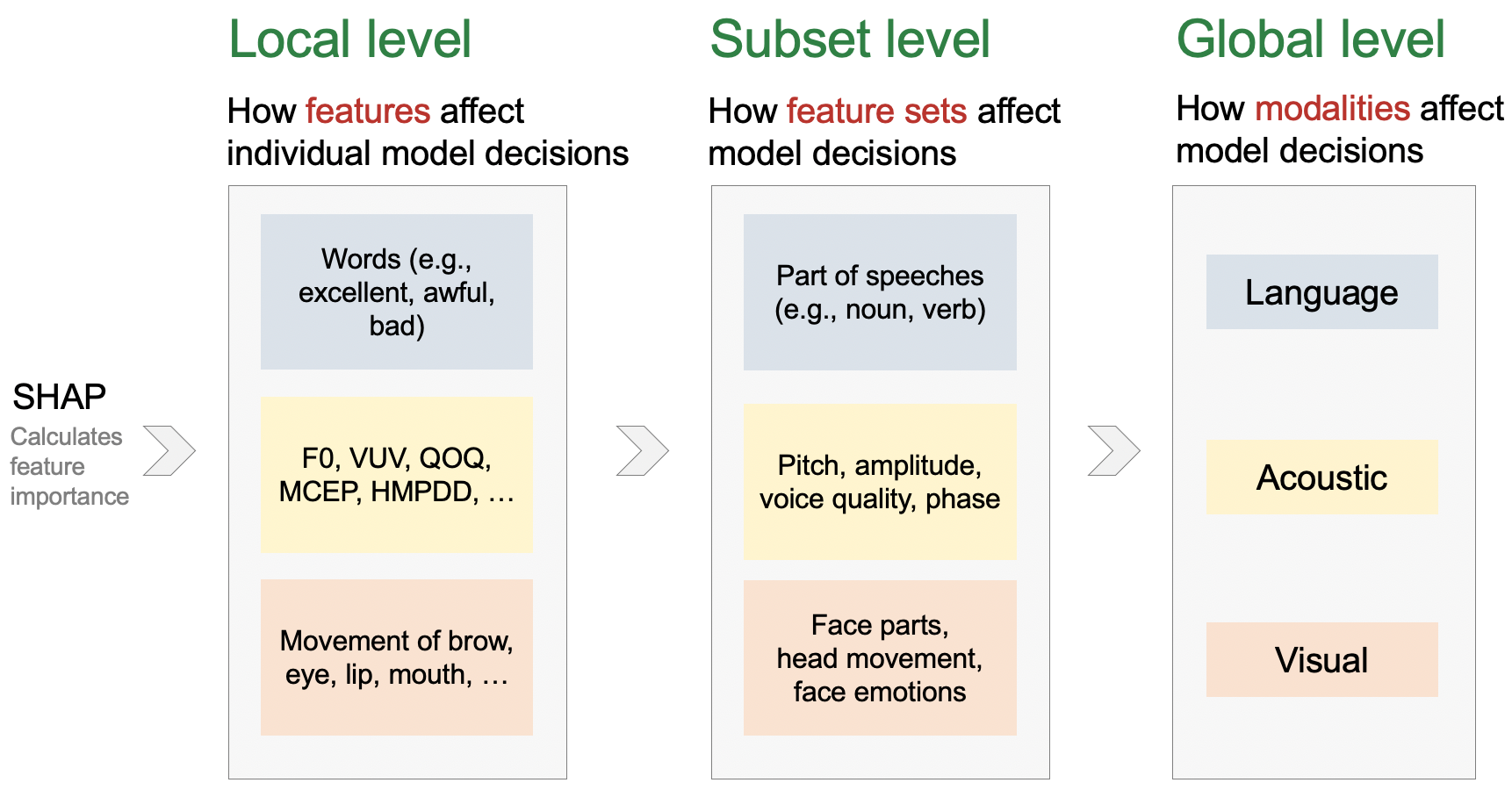
To facilitate a comprehensive understanding of multimodal models, M2Lens offered multi-level and multi-faceted explanations, including the influences of individual modalities and their interplay, and importance of multimodal features.
Case Study: Multimodal Transformer
In this case study, the expert explored and diagnosed a state-of-the-art model, Multimodal Transformer (MulT), for sentiment analysis using the CMU-MOSEI dataset. MulT fuses multimodal inputs with cross-modal transformers for all pairs of modalities, which learn the mappings between the source modality and target modality (e.g., vision → text). Then, the results are passed to sequence models (i.e., self-attention transformers) for final predictions. All the multi-modal features of the input data are aligned at the word level based on the word timestamps. Following the settings of previous work, we trained, validated, and evaluated MulT with the same data splits (training: 16,265, validation: 1,869, and testing: 4,643).
In our paper, we demonstrate how M2Lens helps users understand and diagnose multimodal models for sentiment analysis through two case studies. Below we describe two such examples.
Example I: Dominance of Language Modality
After loading the multimodal transformer in the system, an expert E1 referred to the Summary View to see how individual modalities and their interplay contribute to the model predictions.
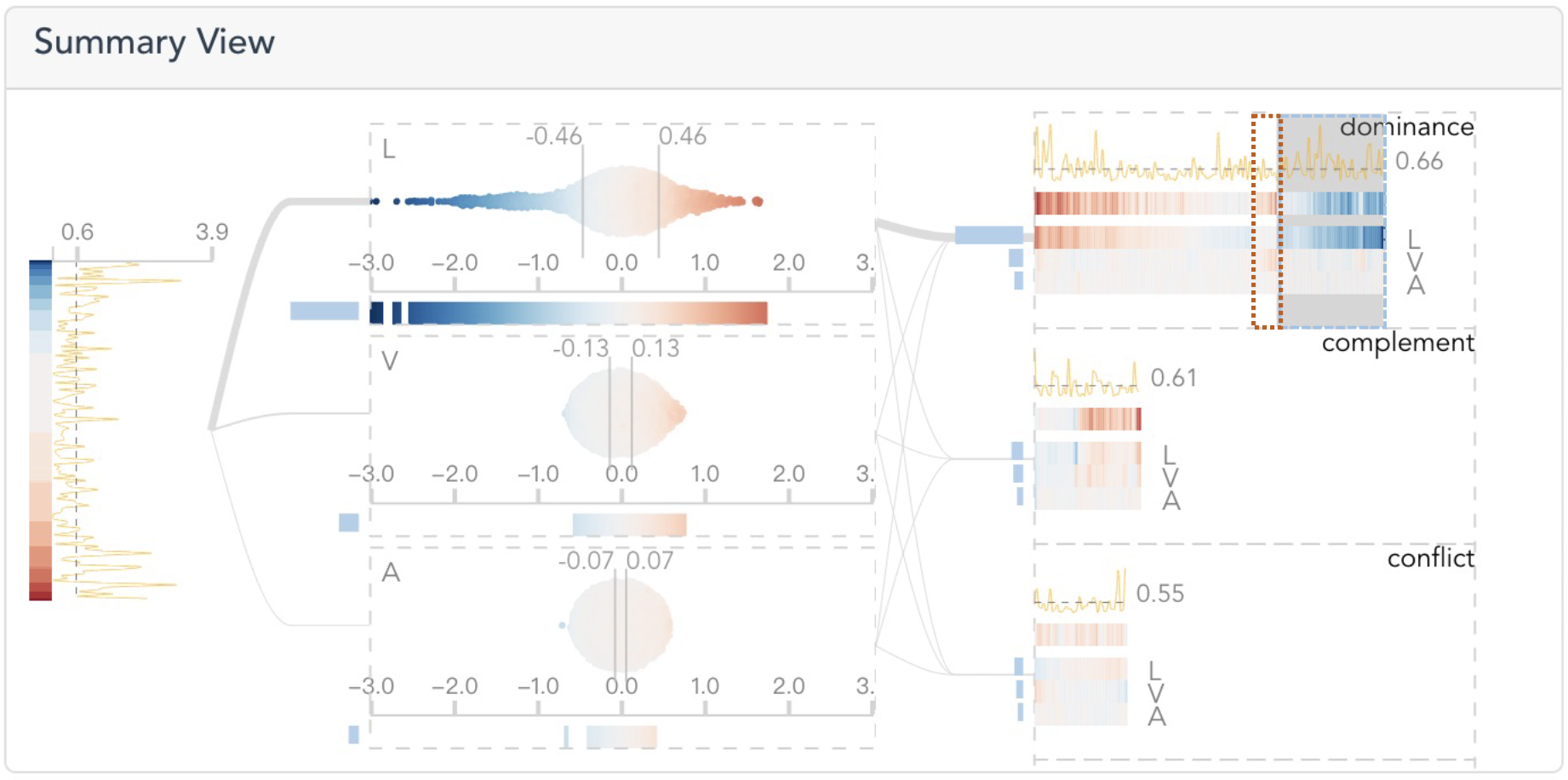
By looking at the second layer, E1 found that the language modality has the largest influence among the three modalities since it has the longest bar to the left and widest range of dots in the bee swarm plot.
In the last layer, within the dominance group, he discovered that the longest bars attach to the language modality, and the color of the prediction barcode aligns well with that of the language barcode. Thus, E1 concluded that the language also plays a leading role in the dominance relationship. He noticed that there are a group of dense blue bars appearing at the end of the language barcode, where the errors are relatively large (as indicated by the yellow curve above the dashed line). He wondered what features or their combinations caused the high errors. Therefore, he brushed the corresponding area of the blue bars.
Then, the Template View lists the feature templates of the selected instance in the Summary View. By sorting them in descending order of error, E1 found that the “PRON + PART” appears at the top with a child feature. Then, he collapsed the row and found that 21 instances contain the word “not”, where it negatively influences the predictions.
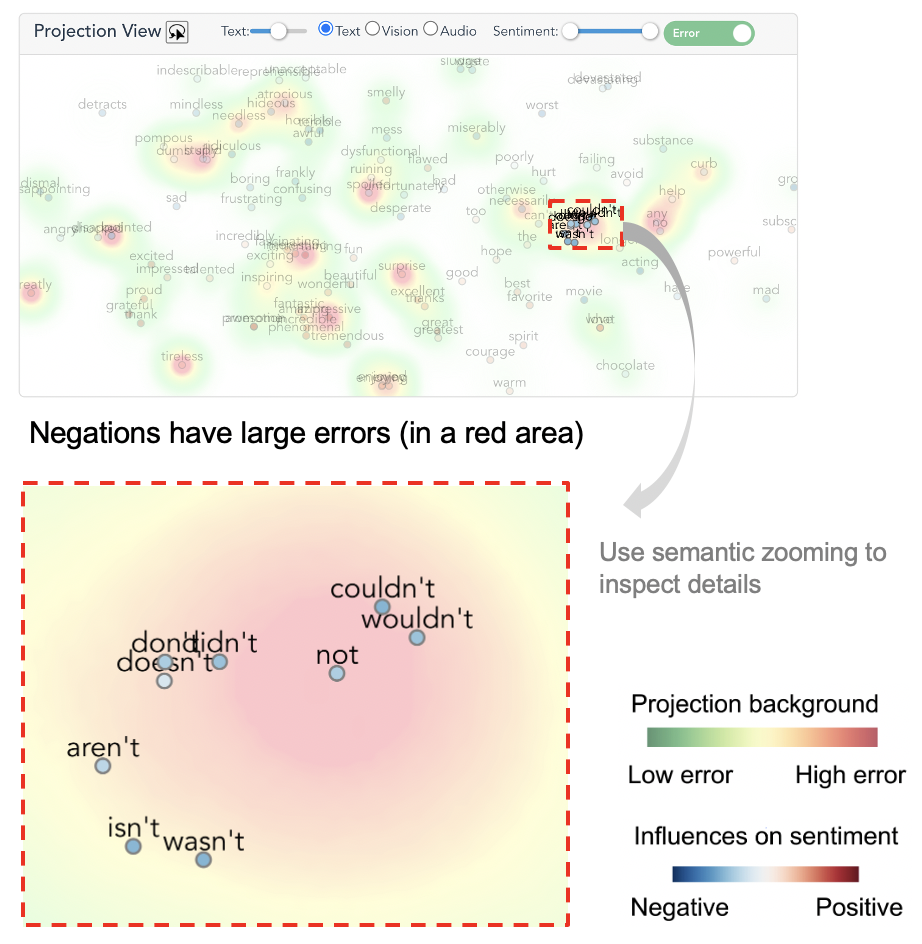
Next, he clicked “not” to see the details about this feature in the Projection View. Zooming in on the word “not”, several similar negative words (e.g., “isn’t”, “wouldn’t”) were observed. E1 speculated that the model could not deal well with negations. Subsequently, he lassoed these words to closely examine the corresponding instances in the Instance View.
When exploring the examples with large errors, E1 noticed that when double negations appear in a sentence (e.g., “not…sin…” and “not…bad…”) , the model tends to treat them separately and regards both of them as indicators for negative sentiment. He thought that augmenting double negation examples or preprocessing them into positive forms may improve the model performance.

Example II: Dominance of Visual Modality
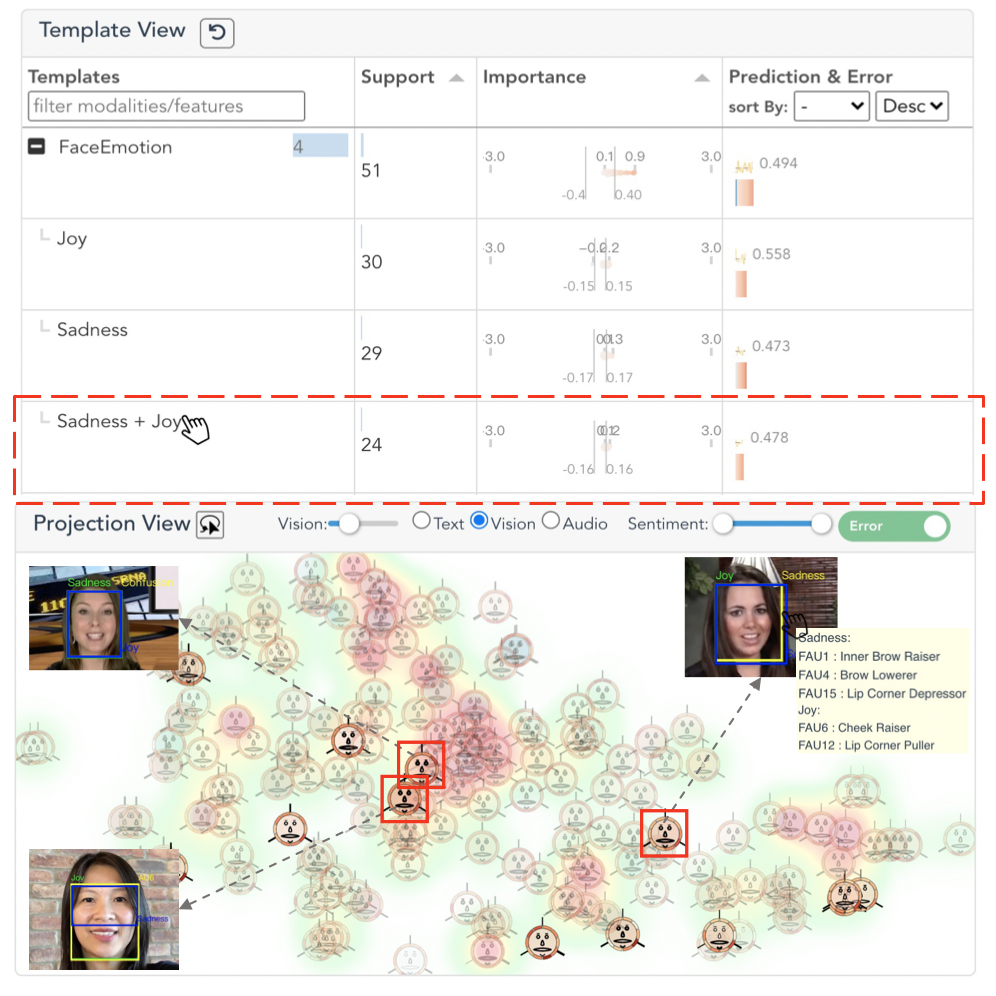
Afterward, E1 referred back to the “dominance” group in the Summary View, where a collection of red bars from the prediction barcode conform with the ones from the visual modality. It indicates that the visual modality dominates the predictions, and the error line chart above suggests a low error rate in contrast with the previous case. Motivated by this observation, E1 brushed the red bars to investigate the patterns in the visual features.
In the Template View, “Face Emotion” has the largest support. After unfolding the row, E1 found that “Sadness + Joy” is a frequent and important combination. This intrigued him to find out how a contrary emotion pair co-occurs. After clicking the template, the corresponding glyphs are highlighted in the Projection View. Most of them were found outside of the red area, which verifies that the instances with “Sadness + Joy” often have small prediction errors. Through browsing the instances and their videos in the Instance View, “Joy” and “Sadness” are often considered important to model predictions. Their co-occurrences may be due to the presence of intense and rich facial expressions in the videos. And the model seemed to capture these important visual facial expressions.
Future Work
In summary, we characterize the intra- and inter-modal interactions learned by a multimodal model for sentiment analysis. Moreover, we provide multi-level and multi-faceted explanations on model behaviors regarding dominant, complementary, and conflicting relationships among modalities.
In the future, we can extend the system to other multimodal NLP tasks (e.g., emotion classification and visual question answering). And we can further conduct a comparative study of multimodal models, determing under what circumstances we should use multimodal models and when uni- or bi-modal models are sufficient for target applications.
M2Lens features
Check out the following video for a quick look at M2Lens’s features.
- Introduction to multimodal sentiment analysis (0:22 – 1:53)
- What have machine learning models learn from data?(1:53 – 2:48)
- Intra- and inter-modal interactions (2:48 – 3:59)
- M2Lens design(3:59 – 7:29)
- Case studies (7:29 – 11:28)

M2Lens: Visualizing and Explaining Multimodal Models for Sentiment Analysis
Xingbo Wang, Jianben He, Zhihua Jin, Muqiao Yang, Yong Wang and Huamin Qu.
IEEE Transactions on Visualization and Computer Graphics (TVCG, IEEE VIS). 2021.🏅 Honorable Mention